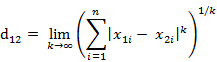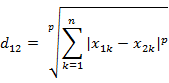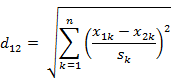Introduction
A virtual private network, or VPN, allows you to securely encrypt traffic as it travels through untrusted networks, such as those at the coffee shop, a conference, or an airport.
IKEv2, or Internet Key Exchange v2, is a protocol that allows for direct IPSec tunneling between the server and client. In IKEv2 VPN implementations, IPSec provides encryption for the network traffic. IKEv2 is natively supported on some platforms (OS X 10.11+, iOS 9.1+, and Windows 10) with no additional applications necessary, and it handles client hiccups quite smoothly.
In this tutorial, you’ll set up an IKEv2 VPN server using StrongSwan on an Ubuntu 18.04 server and connect to it from Windows, macOS, Ubuntu, iOS, and Android clients.
Prerequisites
To complete this tutorial, you will need:
One Ubuntu 18.04 server configured by following the Ubuntu 18.04 initial server setup guide, including a sudo non-root user and a firewall.
Step 1 Installing StrongSwan
First, we’ll install StrongSwan, an open-source IPSec daemon which we’ll configure as our VPN server. We’ll also install the public key infrastructure component so that we can create a certificate authority to provide credentials for our infrastructure.
Update the local package cache and install the software by typing:
$ sudo apt update
$ sudo apt install strongswan strongswan-pki ufw
Now that everything’s installed, let’s move on to creating our certificates.
Step 2 Creating a Certificate Authority
An IKEv2 server requires a certificate to identify itself to clients. To help us create the certificate required, the strongswan-pki package comes with a utility to generate a certificate authority and server certificates. To begin, let’s create a few directories to store all the assets we’ll be working on. The directory structure matches some of the directories in /etc/ipsec.d, where we will eventually move all of the items we create. We’ll lock down the permissions so that our private files can’t be seen by other users:
$ mkdir -p ~/pki/{cacerts,certs,private}
$ chmod 700 ~/pki
Now that we have a directory structure to store everything, we can generate a root key. This will be a 4096-bit RSA key that will be used to sign our root certificate authority.
Execute these commands to generate the key:
ipsec pki --gen --type rsa --size 4096 --outform pem \
> ~/pki/private/ca-key.pem
Now that we have a key, we can move on to creating our root certificate authority, using the key to sign the root certificate:
$ ipsec pki --self --ca --lifetime 3650 --in ~/pki/private/ca-key.pem \
--type rsa --dn "CN=VPN root CA" --outform pem > ~/pki/cacerts/ca-cert.pem
You can change the distinguished name (DN) values to something else to if you would like. The common name here is just the indicator, so it doesn’t have to match anything in your infrastructure.
Now that we’ve got our root certificate authority up and running, we can create a certificate that the VPN server will use.
Step 3 Generating a Certificate for the VPN Server
We’ll now create a certificate and key for the VPN server. This certificate will allow the client to verify the server’s authenticity using the CA certificate we just generated.
First, create a private key for the VPN server with the following command:
$ ipsec pki --gen --type rsa --size 4096 --outform pem > ~/pki/private/server-key.pem
Now, create and sign the VPN server certificate with the certificate authority’s key you created in the previous step. Execute the following command, but change the Common Name (CN) and the Subject Alternate Name (SAN) field to your VPN server’s DNS name or IP address:
$ ipsec pki --pub --in ~/pki/private/server-key.pem --type rsa \
| ipsec pki --issue --lifetime 1825 \
--cacert ~/pki/cacerts/ca-cert.pem \
--cakey ~/pki/private/ca-key.pem \
--dn "CN=server_domain_or_IP" --san "server_domain_or_IP" \
--flag serverAuth --flag ikeIntermediate --outform pem \
> ~/pki/certs/server-cert.pem
Now that we’ve generated all of the TLS/SSL files StrongSwan needs, we can move the files into place in the /etc/ipsec.d directory by typing:
$ sudo cp -r ~/pki/* /etc/ipsec.d/
In this step, we’ve created a certificate pair that would be used to secure communications between the client and the server. We’ve also signed the certificates with the CA key, so the client will be able to verify the authenticity of the VPN server using the CA certificate. Now that have all of the certificates ready, we’ll move on to configuring the software.
Step 4 Configuring StrongSwan
StrongSwan has a default configuration file with some examples, but we will have to do most of the configuration ourselves. Let’s back up the file for reference before starting from scratch:
$ sudo mv /etc/ipsec.conf{,.original}
Create and open a new blank configuration file by typing:
sudo vim /etc/ipsec.conf
First, we’ll tell StrongSwan to log daemon statuses for debugging and allow duplicate connections. Add these lines to the file:
config setup
charondebug="ike 1, knl 1, cfg 0"
uniqueids=no
conn ikev2-vpn
auto=add
compress=no
type=tunnel
keyexchange=ikev2
fragmentation=yes
forceencaps=yes
dpdaction=clear
dpddelay=300s
rekey=no
left=%any
leftid=@server_domain_or_IP
leftcert=server-cert.pem
leftsendcert=always
leftsubnet=0.0.0.0/0
right=%any
rightid=%any
rightauth=eap-mschapv2
rightsourceip=10.10.10.0/24
rightdns=8.8.8.8,8.8.4.4
rightsendcert=never
eap_identity=%identity
Save and close the file once you’ve verified that you’ve configured things as shown.
Now that we’ve configured the VPN parameters, let’s move on to creating an account so our users can connect to the server.
Step 5 Configuring VPN Authentication
Our VPN server is now configured to accept client connections, but we don’t have any credentials configured yet. We’ll need to configure a couple things in a special configuration file called ipsec.secrets:
- We need to tell StrongSwan where to find the private key for our server certificate, so the server will be able to authenticate to clients.
- We also need to set up a list of users that will be allowed to connect to the VPN.
Let’s open the secrets file for editing:
$ sudo vim /etc/ipsec.secrets
First, we’ll tell StrongSwan where to find our private key,Then, we’ll define the user credentials. You can make up any username or password combination that you like:
: RSA "server-key.pem"
your_username : EAP "your_password"
Save and close the file. Now that we’ve finished working with the VPN parameters, we’ll restart the VPN service so that our configuration is applied:
$ sudo systemctl restart strongswan
Now that the VPN server has been fully configured with both server options and user credentials, it’s time to move on to configuring the most important part: the firewall.
Step 6 Configuring the Firewall & Kernel IP Forwarding
With the StrongSwan configuration complete, we need to configure the firewall to forward and allow VPN traffic through.
If you followed the prerequisite tutorial, you should have a very basic UFW firewall enabled. If you don’t yet have UFW configured, you can create a baseline configuration and enable it by typing:
$ sudo ufw allow OpenSSH
$ sudo ufw enable
Now, add a rule to allow UDP traffic to the standard IPSec ports, 500 and 4500:
$ sudo ufw allow 500,4500/udp
Next, we will open up one of UFW’s configuration files to add a few low-level policies for routing and forwarding IPSec packets. Before we do, we need to find which network interface on our server is used for internet access. We can find that by querying for the interface associated with the default route:
$ ip route | grep default
Your public interface should follow the word “dev”. For example, this result shows the interface named eth0, which is highlighted below:
Output
default via 203.0.113.7 dev eth0 proto static
When you have your public network interface, open the /etc/ufw/before.rules file in your text editor:
$ sudo nano /etc/ufw/before.rules
Near the top of the file (before the *filter line), add the following configuration block:
*nat
-A POSTROUTING -s 10.10.10.0/24 -o eth0 -m policy --pol ipsec --dir out -j ACCEPT
-A POSTROUTING -s 10.10.10.0/24 -o eth0 -j MASQUERADE
COMMIT
*mangle
-A FORWARD --match policy --pol ipsec --dir in -s 10.10.10.0/24 -o eth0 -p tcp -m tcp --tcp-flags SYN,RST SYN -m tcpmss --mss 1361:1536 -j TCPMSS --set-mss 1360
COMMIT
*filter
:ufw-before-input - [0:0]
:ufw-before-output - [0:0]
:ufw-before-forward - [0:0]
:ufw-not-local - [0:0]
. . .
Change each instance of eth0 in the above configuration to match the interface name you found with ip route. The *nat lines create rules so that the firewall can correctly route and manipulate traffic between the VPN clients and the internet. The *mangle line adjusts the maximum packet segment size to prevent potential issues with certain VPN clients.
Next, after the *filter and chain definition lines, add one more block of configuration:
. . .
*filter
:ufw-before-input - [0:0]
:ufw-before-output - [0:0]
:ufw-before-forward - [0:0]
:ufw-not-local - [0:0]
-A ufw-before-forward --match policy --pol ipsec --dir in --proto esp -s 10.10.10.0/24 -j ACCEPT
-A ufw-before-forward --match policy --pol ipsec --dir out --proto esp -d 10.10.10.0/24 -j ACCEPT
These lines tell the firewall to forward ESP (Encapsulating Security Payload) traffic so the VPN clients will be able to connect. ESP provides additional security for our VPN packets as they’re traversing untrusted networks.
When you’re finished, save and close the file.
Before we restart the firewall, we’ll change some network kernel parameters to allow routing from one interface to another. Open UFW’s kernel parameters configuration file:
$ sudo nano /etc/ufw/sysctl.conf
We’ll need to configure a few things here:
- First, we’ll enable IPv4 packet forwarding.
- We’ll disable Path MTU discovery to prevent packet fragmentation problems.
- We also won’t accept ICMP redirects nor send ICMP redirects to prevent man-in-the-middle attacks.
The changes you need to make to the file are highlighted in the following code:
. . .
# Enable forwarding
# Uncomment the following line
net/ipv4/ip_forward=1
. . .
# Do not accept ICMP redirects (prevent MITM attacks)
# Ensure the following line is set
net/ipv4/conf/all/accept_redirects=0
# Do not send ICMP redirects (we are not a router)
# Add the following lines
net/ipv4/conf/all/send_redirects=0
net/ipv4/ip_no_pmtu_disc=1
Save the file when you are finished. UFW will apply these changes the next time it starts.
Now, we can enable all of our changes by disabling and re-enabling the firewall:
$ sudo ufw disable
$ sudo ufw enable
You’ll be prompted to confirm the process. Type Y to enable UFW again with the new settings.
Reboot server to make it active.
Step 7 Testing the VPN Connection on iOS, and macOS
Now that you have everything set up, it’s time to try it out. First, you’ll need to copy the CA certificate you created and install it on your client device(s) that will connect to the VPN. The easiest way to do this is to log into your server and output the contents of the certificate file:
$ cat /etc/ipsec.d/cacerts/ca-cert.pem
You’ll see output similar to this:
-----BEGIN CERTIFICATE-----
MIIFQjCCAyqgAwIBAgIIFkQGvkH4ej0wDQYJKoZIhvcNAQEMBQAwPzELMAkGA1UE
. . .
EwbVLOXcNduWK2TPbk/+82GRMtjftran6hKbpKGghBVDPVFGFT6Z0OfubpkQ9RsQ
BayqOb/Q
-----END CERTIFICATE-----
Copy this output to your computer, including the —–BEGIN CERTIFICATE—– and —–END CERTIFICATE—– lines, and save it to a file with a recognizable name, such as ca-cert.pem. Ensure the file you create has the .pem extension.
Alternatively, use SFTP to transfer the file to your computer.
Once you have the ca-cert.pem file downloaded to your computer, you can set up the connection to the VPN.
Connecting from iOS
To configure the VPN connection on an iOS device, follow these steps:
- Send yourself an email with the root certificate attached.
- Open the email on your iOS device and tap on the attached certificate file, then tap Install and enter your passcode. Once it installs, tap Done.
- Go to Settings, General, VPN and tap Add VPN Configuration. This will bring up the VPN connection configuration screen.
- Tap on Type and select IKEv2.
- In the Description field, enter a short name for the VPN connection. This could be anything you like.
- In the Server and Remote ID field, enter the server’s domain name or IP address. The Local ID field can be left blank.
- Enter your username and password in the Authentication section, then tap Done.
- Select the VPN connection that you just created, tap the switch on the top of the page, and you’ll be connected.
Connecting from macOS
Follow these steps to import the certificate:
- Double-click the certificate file. Keychain Access will pop up with a dialog that says “Keychain Access is trying to modify the system keychain. Enter your password to allow this.”
- Enter your password, then click on Modify Keychain
- Double-click the newly imported VPN certificate. This brings up a small properties window where you can specify the trust levels. Set IP Security (IPSec) to Always Trust and you’ll be prompted for your password again. This setting saves automatically after entering the password.
Now that the certificate is important and trusted, configure the VPN connection with these steps:
- Go to System Preferences and choose Network.
- Click on the small “plus” button on the lower-left of the list of networks.
- In the popup that appears, Set Interface to VPN, set the VPN Type to IKEv2, and give the connection a name.
- In the Server and Remote ID field, enter the server’s domain name or IP address. Leave the Local IDblank.
- Click on Authentication Settings, select Username, and enter your username and password you configured for your VPN user. Then click OK.
Finally, click on Connect to connect to the VPN. You should now be connected to the VPN.
Link: https://www.digitalocean.com/community/tutorials/how-to-set-up-an-ikev2-vpn-server-with-strongswan-on-ubuntu-18-04-2