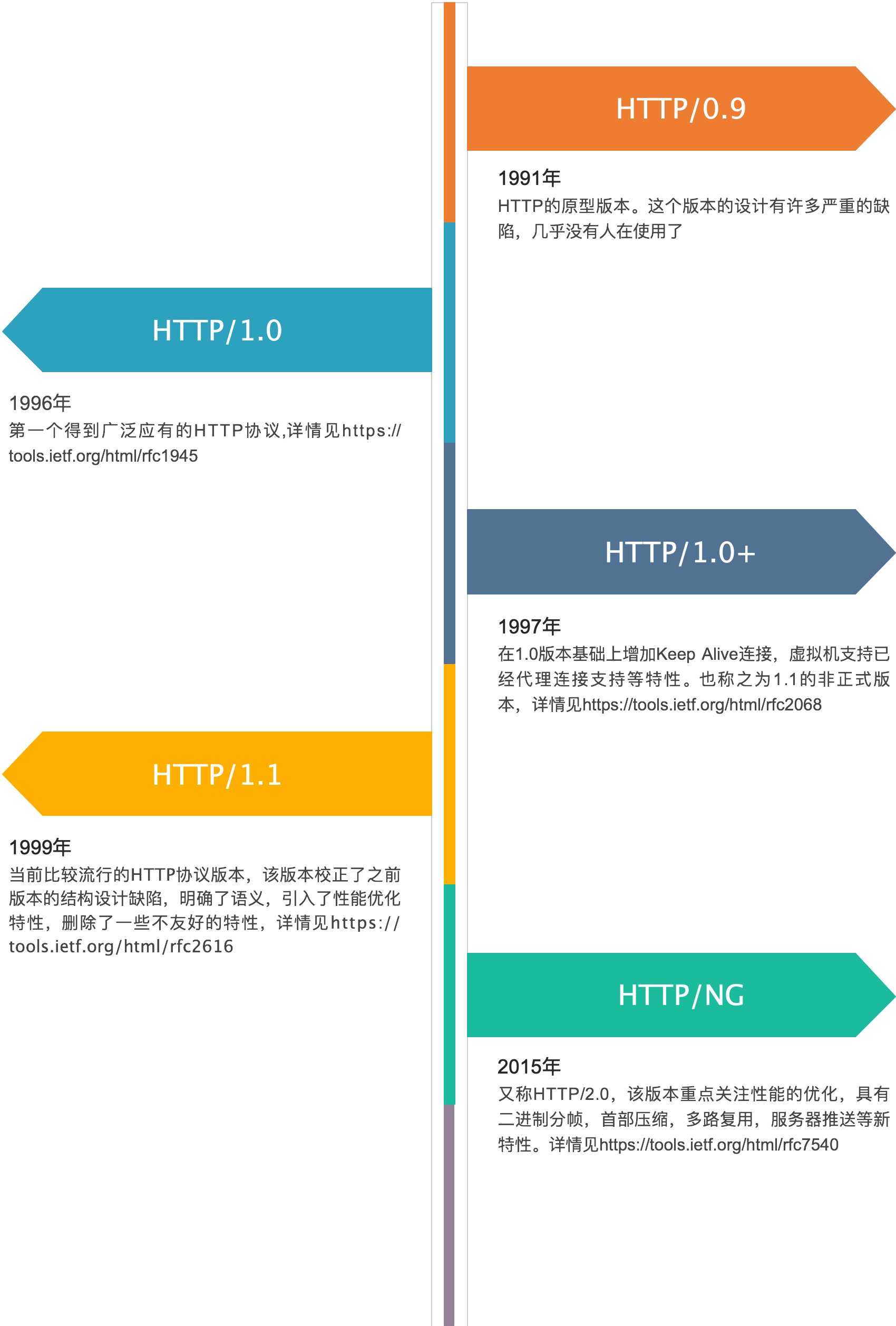
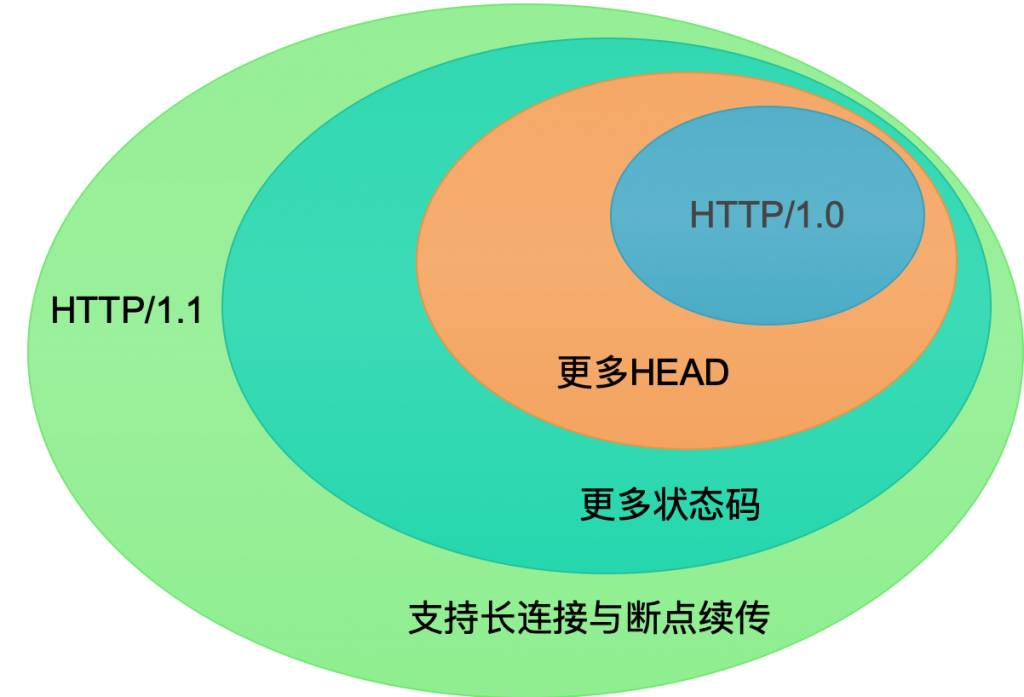
一、OSI模型和TCP/IP模型
- OSI(Open System Interconnect),即开放式系统互联。 一般都叫OSI参考模型,是ISO(国际标准化组织)组织在1985年研究的网络互连模型
- TCP/IP协议族是一个四层协议系统,自底而上分别是数据链路层、网络层、传输层和应用层。每一层完成不同的功能,且通过若干协议来实现,上层协议使用下层协议提供的服务
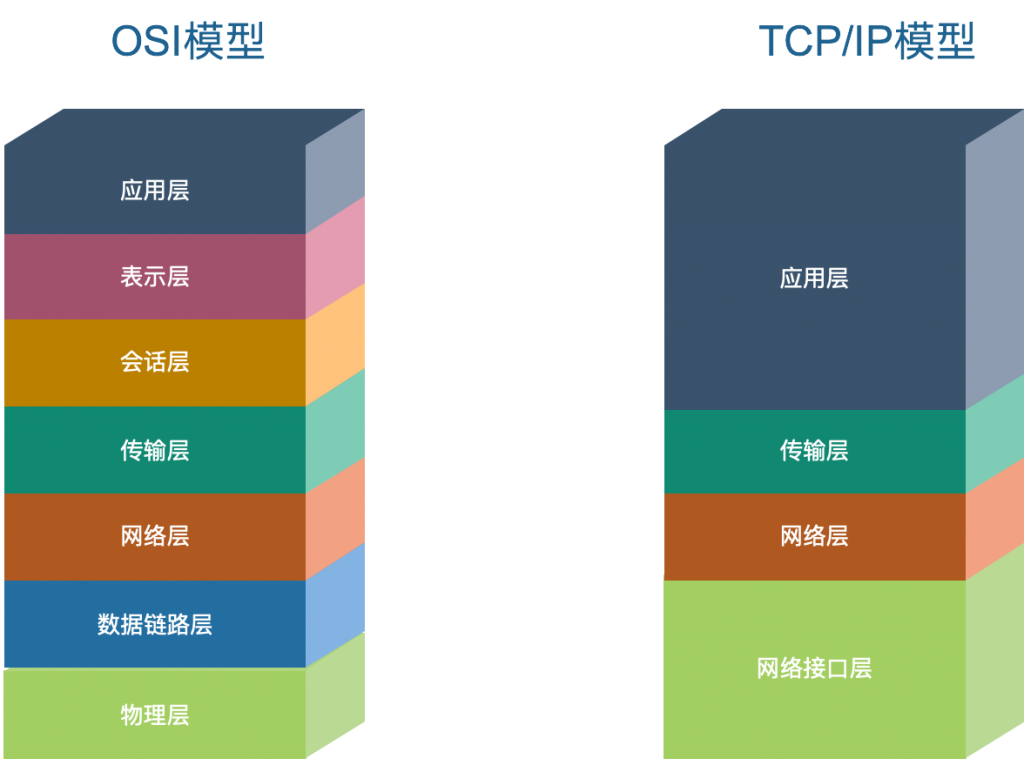
- OSI模型
- 应用层:是为计算机用户提供应用接口,也为用户直接提供各种网络服务。我们常见应用层的网络服务协议有:HTTP,HTTPS,FTP,POP3、SMTP等
- 表示层:提供各种用于应用层数据的编码和转换功能,确保一个系统的应用层发送的数据能被另一个系统的应用层识别。如果必要,该层可提供一种标准表示形式,用于将计算机内部的多种数据格式转换成通信中采用的标准表示形式。数据压缩和加密也是表示层可提供的转换功能之一
- 会话层:负责建立、管理和终止表示层实体之间的通信会话
- 传输层:建立了主机端到端的链接,传输层的作用是为上层协议提供端到端的可靠和透明的数据传输服务,包括处理差错控制和流量控制等问题。该层向高层屏蔽了下层数据通信的细节,使高层用户看到的只是在两个传输实体间的一条主机到主机的、可由用户控制和设定的、可靠的数据通路。我们通常说的,TCP UDP就是在这一层
- 网络层:通过IP寻址来建立两个节点之间的连接,为源端的运输层送来的分组,选择合适的路由和交换节点,正确无误地按照地址传送给目的端的运输层。就是通常说的IP层。这一层就是我们经常说的IP协议层
- 数据链路层:将比特组合成字节,再将字节组合成帧,使用链路层地址 (以太网使用MAC地址)来访问介质,并进行差错检测
- 物理层:实际最终信号的传输是通过物理层实现的。通过物理介质传输比特流。规定了电平、速度和电缆针脚。常用设备有(各种物理设备)集线器、中继器、调制解调器、网线、双绞线、同轴电缆。这些都是物理层的传输介质
- TCP/IP模型
- 应用层:负责处理特定的应用程序细节。简单网络管理SNMP协议,简单网络传输SMTP,域名解析DNS,文件下载FTP协议,远程协助Telnet协议,超文本传输HTTP等等
- 传输层:主要为两台主机上的应用提供端到端的通信。TCP协议和UDP协议
- 网络层:处理分组在网络中的活动,比如分组的选路。IP协议等
- 网络接口层:包括操作系统中的设备驱动程序、计算机中对应的网络接口卡
二、HTTP与TCP/IP
HTTP通信是由TCP/IP协议承载的,因此HTTP协议的需要进行三次握手才能建立连接,经过四次挥手才能断开连接。
2.1 建立连接
- 第一次握手:Client将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN_SENT状态,等待Server确认
- 第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态
- 第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了

2.2 断开连接
- 第一次挥手:Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态
- 第二次挥手:Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态
- 第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态
- 第四次挥手:Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号+1,Server进入CLOSED状态,完成四次挥手

2.3 浏览器对同一域名下的并发限制
各版本浏览器对同一域名下的并发连接数有一定限制,具体详情如下:
| 浏览器 | HTTP/1.1 | HTTP/1.0 |
| IE 11 | 6 | 6 |
| IE 10 | 6 | 6 |
| IE 9 | 10 | 10 |
| IE 8 | 6 | 6 |
| IE 6, 7 | 2 | 4 |
| Firefox | 6 | 6 |
| Safari 3,4 | 4 | 4 |
| Chrome 4+ | 6 | 6 |