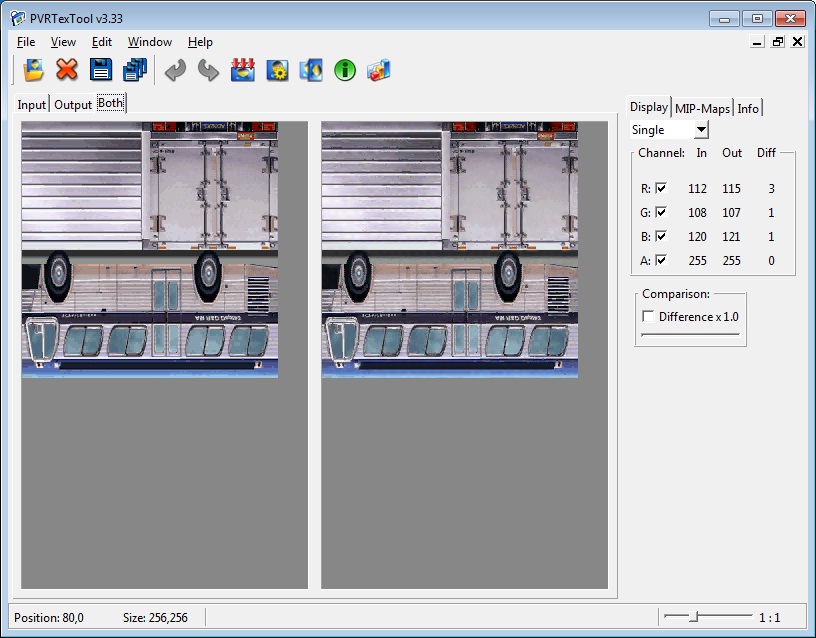
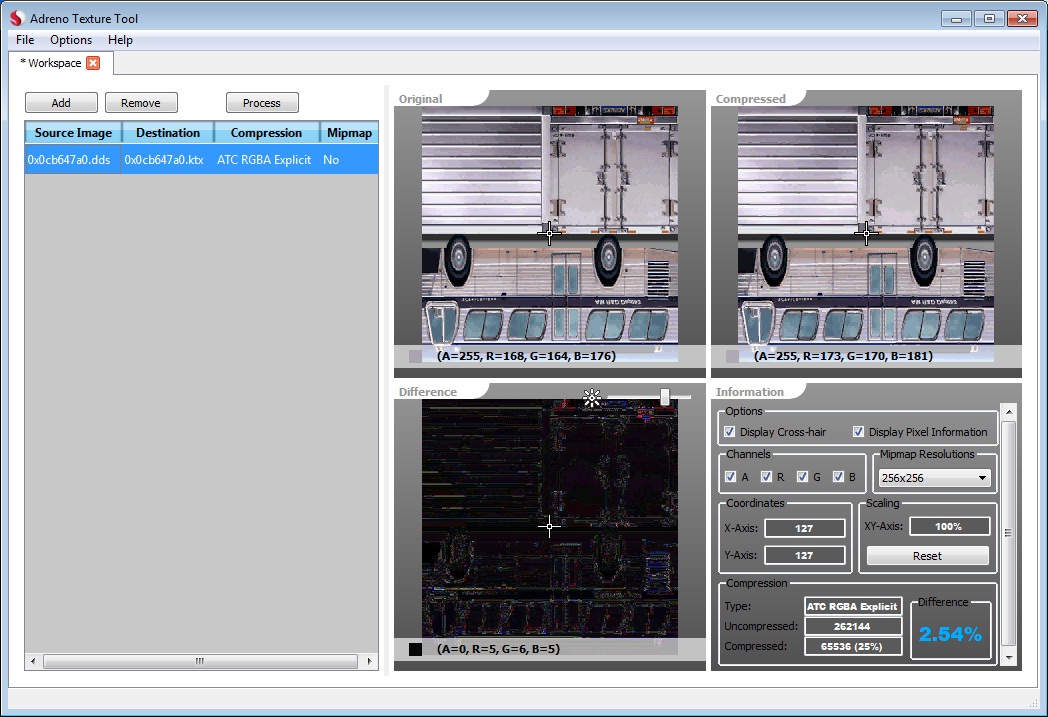
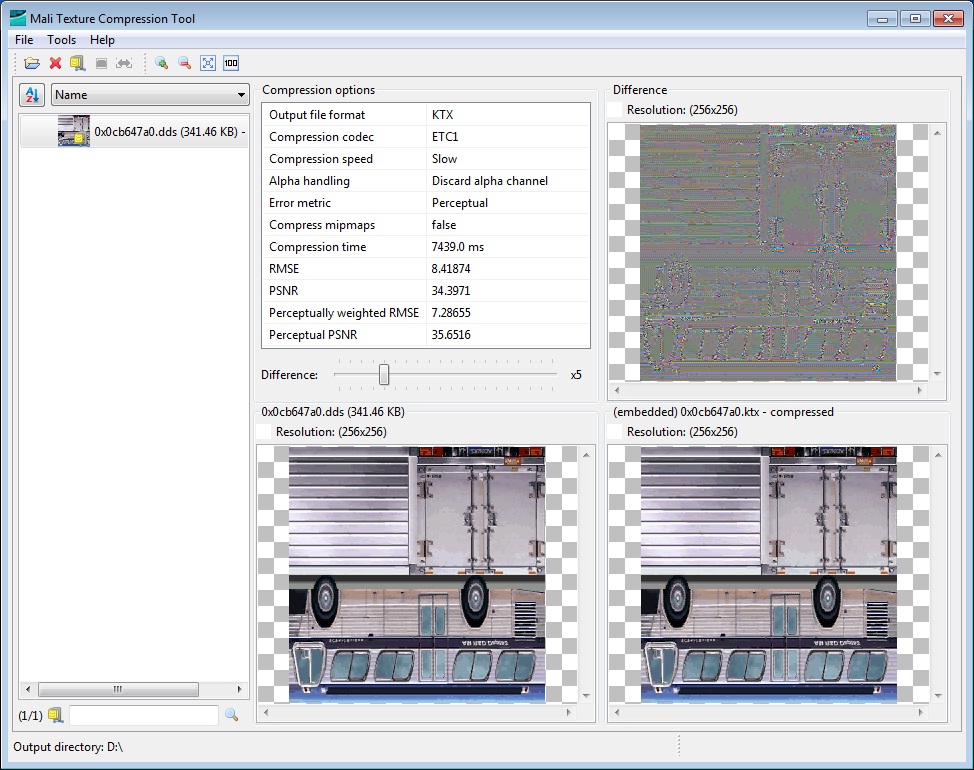
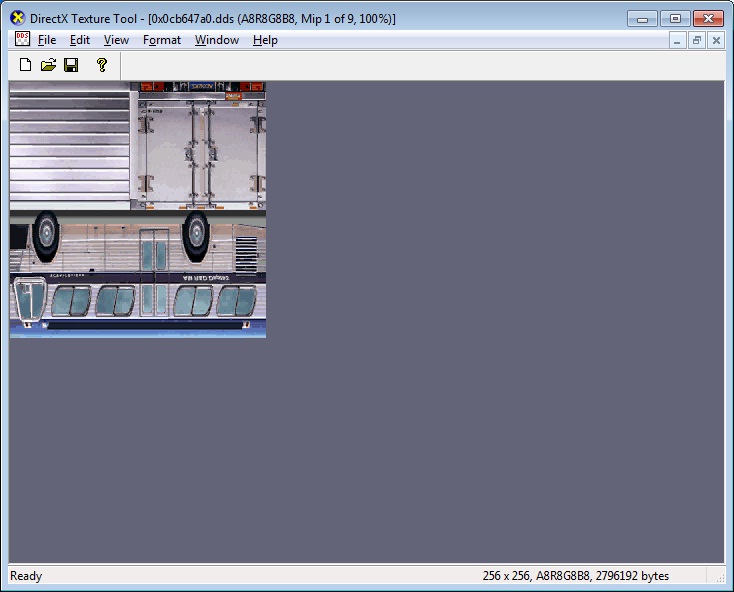
1、ETC1图片是android下通用的压缩纹理,几乎所有的android机器都支持,是opengles2.0的标准。不像pvrtc4只是部分powervr的显卡支持。
ETC1图片不支持半透明(有替代方案可以使etc1图片兼容半透明显示),内存占用只有正常RGBA8888的八分之一(一个像素0.5个字节),并且具备极高的加载速度。ETC1的图片大小只跟图片尺寸相关,在大小上无法媲美jpg或者png8的图片。
2、cocos2d-x早期使用android提供的ETC1Util来加载纹理,后面经过一次优化,改变成直接读取文件的加载方式。 也就是说ETC1文件前面16个字节是文件头,包含文件宽高等信息。 除开这16个字节,剩下的就是图片像素数据,这些数据可以直接传递给显卡使用glCompressedTexImage2D来创建纹理。
3、同样在这次优化中,加入了软件解压ETC1的功能,这样windows等桌面平台也可以使用ETC1的图片了(虽然没有任何优势可言)。但是实现有一些bug,导致不兼容非2的整次幂的图片。修改如下
- //if it is not gles or device do not support ETC, decode texture by software
- int bytePerPixel = 3;
- GLenum fallBackType = GL_UNSIGNED_BYTE;
- /*bool fallBackUseShort = false;
- if(fallBackUseShort)
- {
- bytePerPixel = 2;
- fallBackType = GL_UNSIGNED_SHORT_5_6_5;
- }
- */
- unsigned int stride = _width * bytePerPixel;
- std::vector<unsigned char> decodeImageData(((stride + 3) &~ 3) * ((_height + 3) &~3));
- etc1_decode_image(etcFileData + ETC_PKM_HEADER_SIZE, &decodeImageData[0], _width, _height, bytePerPixel, ((stride + 3) &~ 3));
- //set decoded data to gl
- glGenTextures(1, &_name);
- glBindTexture(GL_TEXTURE_2D, _name);
- glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
- glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
- glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
- glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, _width, _height, 0, GL_RGB, fallBackType, &decodeImageData[0]);
- glBindTexture(GL_TEXTURE_2D, 0);
- delete[] etcFileData;
- etcFileData = NULL;
- return true;
注意其中两句
std::vector<unsigned char> decodeImageData(((stride + 3) &~ 3) * ((_height + 3) &~3));
etc1_decode_image(etcFileData + ETC_PKM_HEADER_SIZE, &decodeImageData[0], _width, _height, bytePerPixel, ((stride + 3) &~ 3));
分配内存必须能够容纳下图片数据,而ETC1图片会进行4字节对齐(圆整),所以宽高不能直接使用原始图片数据。 当然,不修改的话对于2的整次幂的图片也是没有问题的,因为本身就是对齐的,不需要圆整了。
4、android下部分机器兼容非2的整次幂的etc1图片,但是同样也有部分机器不兼容。遇到非2的整次幂的图片会渲染错误甚至崩溃。所以android下使用etc1图片需要进行2的整次幂的扩展。如果大量零碎文件的话,考虑使用TexturePacker打包图片
5、etc1对透明图片的支持。 etc1不支持透明图片,同样cocos2d-x对etc1也不支持透明图片的显示。虽然图片格式上面不支持,但是我们可以通过技术手段间接达到透明etc1图片渲染的目的。详细内容可以参考这里 。
有两种方案可以选择,一种是通过Mali工具生成pkm文件时选择Create atlas,这样就生成了一张拼接在一起的纹理。这张纹理上半部分是原始图片(无alpha信息),下半部分是alpha信息图片。在渲染的时候使用特殊的shader进行渲染。这个改动是比较小的。
另一种方案是创建两张分离的图片,分别是原始图片和alpha图片。渲染时加载这两张纹理,然后alpha图片当做参数传递给原始图片的shader。
我使用的是第一种方案。修改后的shader如下(注意,这个shader是新增的,并且是只有这种打包的etc1图片才使用这个shader,未打包的无透明色的etc1图片和png图片依然使用原来的shader) 只需要修改像素着色器代码,顶点着色器代码不变。 由于现在etc支持透明显示了,所以bool CCTexture2D::initWithETCFile(const char* file)中m_bHasPremultipliedAlpha要置为false,开启alpha blend来渲染图片
- #ifdef GL_ES
- precision lowp float;
- #endif
- varying vec4 v_fragmentColor;
- varying vec2 v_texCoord;
- uniform sampler2D CC_Texture0;
- void main()
- {
- gl_FragColor = vec4(texture2D(CC_Texture0, vec2(v_texCoord.x, v_texCoord.y)).xyz, texture2D(CC_Texture0, vec2(v_texCoord.x, v_texCoord.y + 0.5)).r);
- }
6、使用etc1图片可以极大的减少内存,并且加快加载速度。 我做过一个简单的测试,80k的png8的图片加载需要消耗117ms,同样的etc1图片(经过扩展有1mb大小)加载消耗40ms。这个已经是极限情况。 一般来说同样大小的etc1图片加载速度要快5~10倍。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~下面新的研究成果~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
7、关于PremultipliedAlpha的理解。 cocos2d-x的CCTexture2D中有一个m_bHasPremultipliedAlpha的属性。我们使用TexturePacker中导出pvr图片时也有提示开启PVRImagesHavePremultipliedAlpha这个选项。 虽然PremultipliedAlpha就是图片的颜色在输出的时候已经预先乘以alpha色了,所以渲染的时候图片的RGB就需要再次乘以alpha色了,这个在一定程度上可以提高运行效率。所以TexturePacker推荐开启PremultipliedAlpha选项,XCode导出png图片的时候以及UIImage加载图片的时候都会使用PremultipliedAlpha。 这个有一点恶心的地方就是,我们无法通过一个图片属性判断它是否是是PremultipliedAlpha的,只能通过肉眼或者是一个并不准确的公式来判断。
我们还可以进一步去理解这个设置。一般来说,半透明图片渲染使用的是alpha blend 参见CCSprite::updateBlendFunc()这个函数。
- void CCSprite::updateBlendFunc(void)
- {
- CCAssert (! m_pobBatchNode, “CCSprite: updateBlendFunc doesn’t work when the sprite is rendered using a CCSpriteBatchNode”);
- // it is possible to have an untextured sprite
- if (! m_pobTexture || ! m_pobTexture->hasPremultipliedAlpha())
- {
- m_sBlendFunc.src = GL_SRC_ALPHA;
- m_sBlendFunc.dst = GL_ONE_MINUS_SRC_ALPHA;
- setOpacityModifyRGB(false);
- }
- else
- {
- m_sBlendFunc.src = CC_BLEND_SRC;
- m_sBlendFunc.dst = CC_BLEND_DST;
- setOpacityModifyRGB(true);
- }
- }
正常来说,半透明图片渲染使用的是 GL_SRC_ALPHA GL_ON_MINUS_SRC_ALPHA这个选项 代表的意思就是: 源(图片)像素*源因子(源alpha) + 目标(屏幕)像素*目标因子(1-源alpha)。 通过这个公式可以达到渲染半透明图片的目的。
如果图片有PremultipliedAlpha,再使用这个公式就不对了,图片明显变暗,因为图片的rgb已经乘以alpha了,再乘一次图片自然就变黑一点。 这个时候渲染的公式就变为:
源像素 + 目标像素*(1-源alpha)。 虽然图片依然是半透明的,但是处理源像素时不再分别乘alpha了。
8、为什么要特意提这个属性呢? 因为ETC1图片在加载的时候默认开启了PremultipliedAlpha,一般不透明的图片处理起来没有问题(正常的etc1图片就是不透明的),但是参见上面我们的透明etc1图片渲染解决方案,实际图片在渲染的时候是可以达到半透明的效果的。所以我们有两个选择,一个是默认关闭PremultipliedAlpha,另一个是默认开启PremultipliedAlpha然后shader中分别把rgb乘以alpha。 具体是alpha blend效率高还是shader中效率高我还没有测试。
9、使用上面的shader在渲染的时候windows下正常,但是android下会出现大量的锯齿。一开始以为是mipmap没有开启的缘故,但是使用mipmap(后面会介绍)后,依然无法解决问题。后面发现cocos2d-x中shader默认使用的低精度浮点数
- #ifdef GL_ES \n\
- precision lowp float; \n\
- #endif \n\
低精度浮点数有效位数因显卡而异,但是不高是肯定的。如果我们没有特殊的运算,低精度足够使用。但是一旦我们有*0.5之类的运算,那么低精度浮点数很容易丢失数据,那表现出来就是各种锯齿。 所以在新的shader代码中删除了这个指令。 另外某些文档说,使用低精度无助于效率提升,因为最终渲染的时候还是要转回中精度(中精度是默认选项,部分高级显卡支持高精度)
10、最终修改后的shader如下
顶点shader (我们把部分运算移动到顶点shader中,而不是每个像素进行计算,这个可以提升运行效率)
- attribute vec4 a_position;
- attribute vec2 a_texCoord;
- attribute vec4 a_color;
- varying vec4 v_fragmentColor;
- varying vec2 v_texCoord;
- varying vec2 v_alphaCoord;
- void main()
- {
- gl_Position = CC_MVPMatrix * a_position;
- v_fragmentColor = a_color;
- v_texCoord = a_texCoord * vec2(1.0, 1.0);
- v_alphaCoord = v_texCoord + vec2(0.0, 0.5);
- }
像素shader
- varying vec4 v_fragmentColor;
- varying vec2 v_texCoord;
- varying vec2 v_alphaCoord;
- uniform sampler2D CC_Texture0;
- void main()
- {
- vec4 v4Colour = texture2D(CC_Texture0, v_texCoord);
- v4Colour.a = texture2D(CC_Texture0, v_alphaCoord).r;
- v4Colour.xyz = v4Colour.xyz * v4Colour.a;
- gl_FragColor = v4Colour * v_fragmentColor;
- //gl_FragColor = vec4(texture2D(CC_Texture0, vec2(v_texCoord.x, v_texCoord.y)).xyz, texture2D(CC_Texture0, vec2(v_texCoord.x, v_texCoord.y + 0.5)).r);
- }
关于shader需要说明三点,在顶点shader中有这么一条指令 v_texCoord = a_texCoord * vec2(1.0, 1.0); 因为ETC1需要2的整次幂,所以我们的图片基本上都有扩展,那也就意味着会设置setTextureRect,如果设置了这个,那么a_texCoord就是我们指定的大小,所以这里去的是(1.0, 1.0),如果没有setTextureRect,那么a_texCoord就是全部的贴图大小,也就是两倍的正常大小,那么这个时候取的就应该是(1.0, 0.5)。 最终我的解决方法是所有的使用这个shader的图片都设置一下大小。这样shader就统一了。
在像素着色器代码中有v4Colour.xyz = v4Colour.xyz * v4Colour.a; 这个就跟上面说的PremultipliedAlpha有关系。我们在shader中预先乘以alpha。
这个shader的使用条件,只有带透明的etc1图片(通过工具导出时进行了自动拼接)才能使用这个shader进行渲染,否则都会出错。这个我们要在代码中进行判断。
- glTexParameteri(target, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
- glTexParameteri(target, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
一般来说,纹理通过
- if (isMipmapped) {
- /* Enable bilinear mipmapping */
- glTexParameteri(target, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_NEAREST);
- } else {
- glTexParameteri(target, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
- }
这个来进行抗锯齿等操作,但是如果在图片边缘的时候计算就会有问题,因为外部没有像素了,而图片本身像素为半透明,那么计算的时候很有可能计算出黑色,那么就显示出黑边了。
- void CCTexture2D::generateMipmap()
- {
- CCAssert( m_uPixelsWide == ccNextPOT(m_uPixelsWide) && m_uPixelsHigh == ccNextPOT(m_uPixelsHigh), “Mipmap texture only works in POT textures”);
- ccGLBindTexture2D( m_uName );
- glGenerateMipmap(GL_TEXTURE_2D);
- m_bHasMipmaps = true;
- }
也可以在生成图片的时候直接创建mipmap的图片。 etc1貌似不支持内存中直接生成。 开启mipmap进行渲染会多30%左右的内存开销,但是如果图片缩小渲染的话,会提高运行效率,并且会提高画质(直接缩小可能某些像素通过11中提到的纹理过滤计算起来会有偏差,但是使用预先缩小的图片就可以达到自己满意的效果)。 而etc1的话在创建图片的时候开启mipmap会多创建n张缩小纹理,对应文件体积就增大了,最大会增加30%~50%。 这个我们看情况使用,部分核心的重要的图片开启mipmap。 加载图片成为mipmap比较简单 glTexImage2D(GL_TEXTURE_2D, 0, s_compressFormat_RGBA, (GLsizei)pixelsWide, (GLsizei)pixelsHigh, 0, GL_RGBA, GL_UNSIGNED_BYTE, data); 这个是提交纹理数据的函数,其中第二是mipmap等级,穿n就对应n级的mipmap,也就是说,如果pkm的etc1图片要支持mipmap,就需要自己写代码,另加载1~n张纹理,然后使用glTexImage2D这个函数把这n张纹理提交给显卡。
- bool CCTextureETC::initWithKtxData(etc1_byte* pData, int len)
- {
- GLuint texture = 0;
- GLenum target;
- GLboolean isMipmapped;
- GLenum glerror;
- GLubyte* pKvData;
- unsigned int kvDataLen;
- KTX_dimensions dimensions;
- KTX_error_code ktxerror;
- KTX_hash_table kvtable;
- GLint sign_s = 1, sign_t = 1;
- ktxerror = ktxLoadTextureM(pData, len, &_name, &target, &dimensions, &isMipmapped, &glerror, &kvDataLen, &pKvData);
- if (KTX_SUCCESS == ktxerror) {
- _width = dimensions.width;
- _height = dimensions.height;
- ktxerror = ktxHashTable_Deserialize(kvDataLen, pKvData, &kvtable);
- if (KTX_SUCCESS == ktxerror) {
- GLubyte* pValue;
- unsigned int valueLen;
- if (KTX_SUCCESS == ktxHashTable_FindValue(kvtable, KTX_ORIENTATION_KEY,
- &valueLen, (void**)&pValue))
- {
- char s, t;
- if (_snscanf((const char*)pValue, valueLen, KTX_ORIENTATION2_FMT, &s, &t) == 2) {
- if (s == ‘l’) sign_s = -1;
- if (t == ‘d’) sign_t = -1;
- }
- }
- ktxHashTable_Destroy(kvtable);
- free(pKvData);
- }
- // 加载成功
- if (isMipmapped) {
- /* Enable bilinear mipmapping */
- glTexParameteri(target, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_NEAREST);
- } else {
- glTexParameteri(target, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
- }
- glTexParameteri(target, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
- glTexParameteri(target, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
- glTexParameteri(target, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
- glBindTexture(target, 0);// 这句很重要,否则会有一些诡异的渲染问题
- return true;
- }
- return false;
- }
转载自: http://blog.csdn.net/langresser_king/article/details/9339313