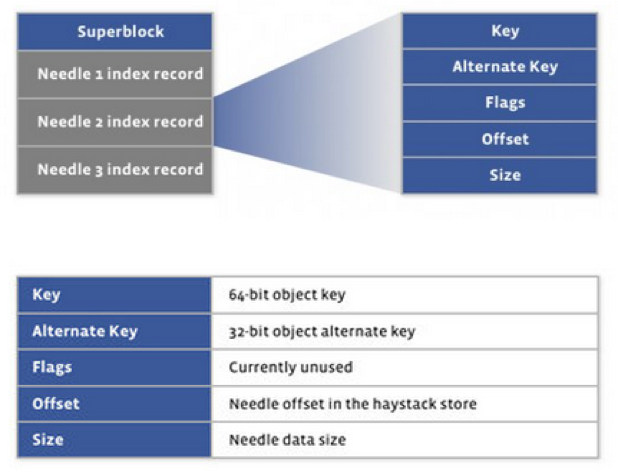
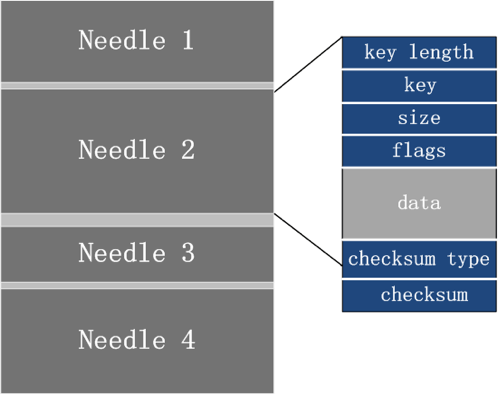
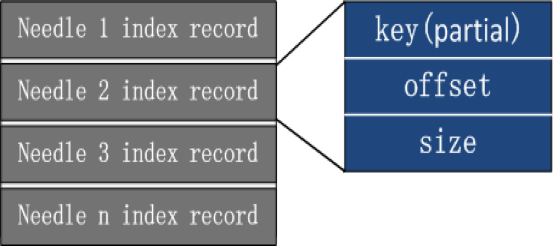
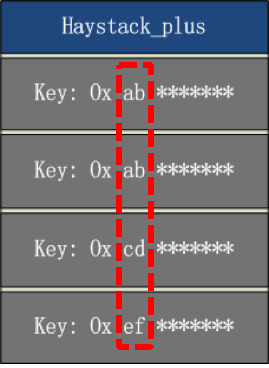
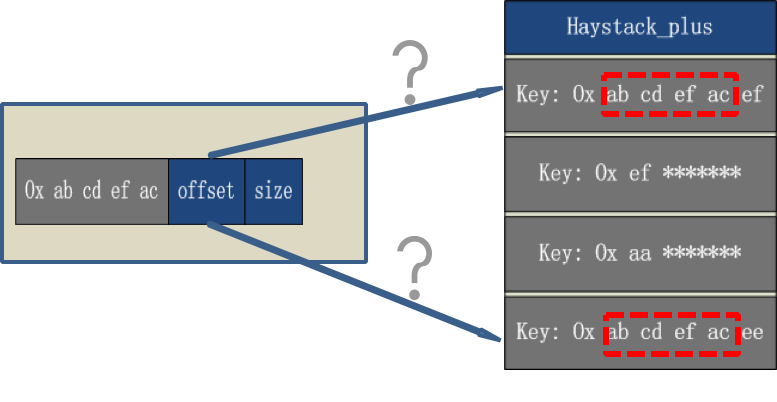
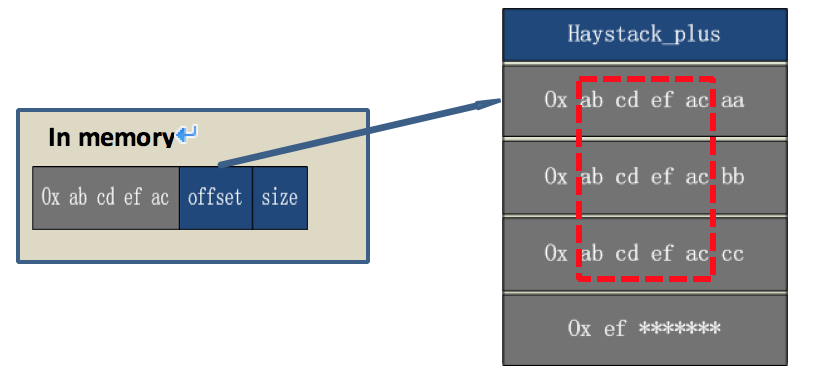
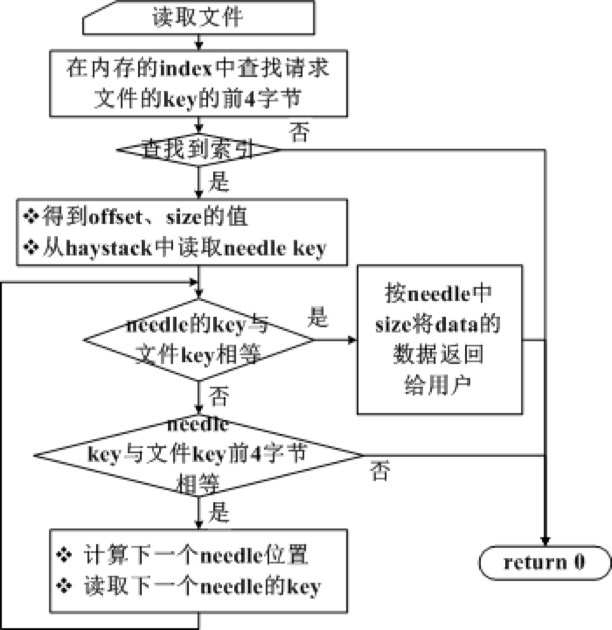
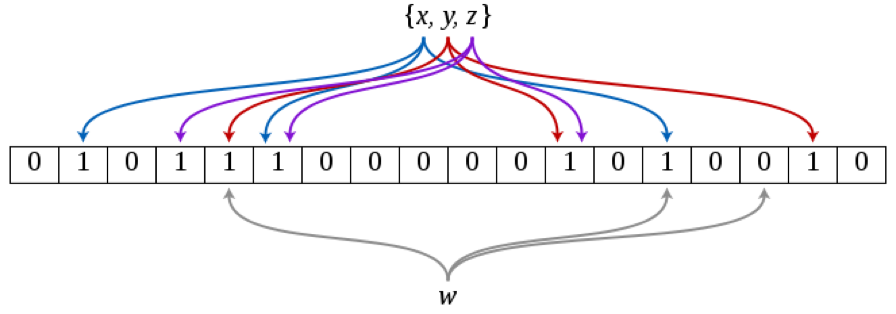
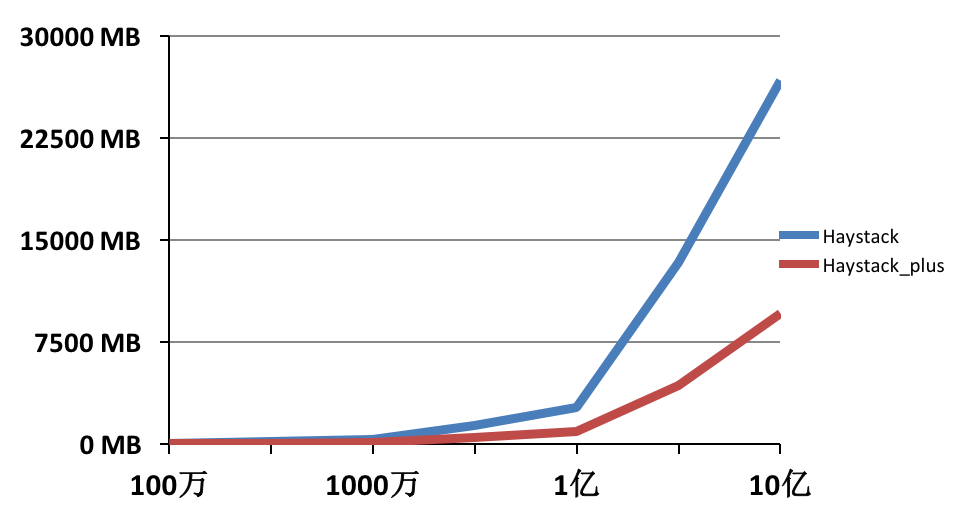
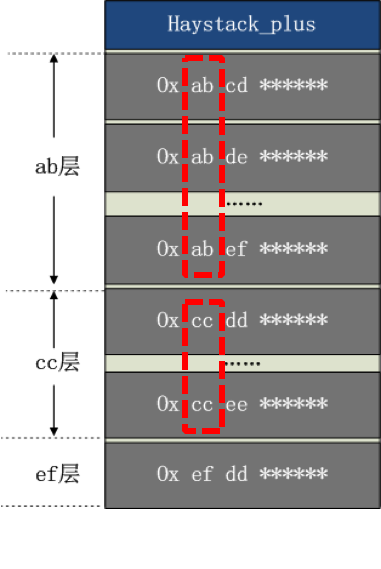
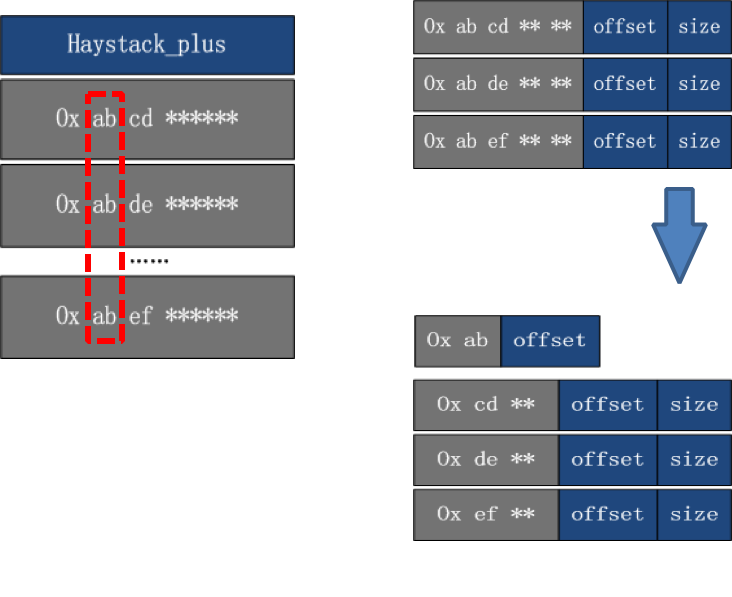
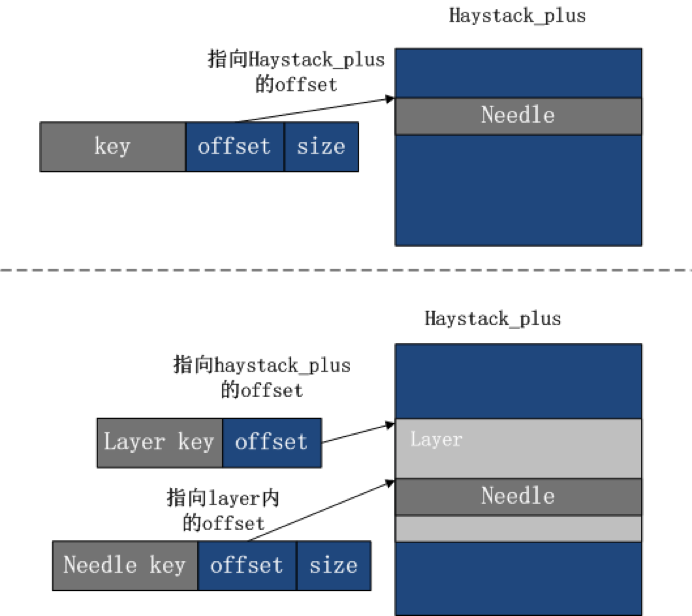
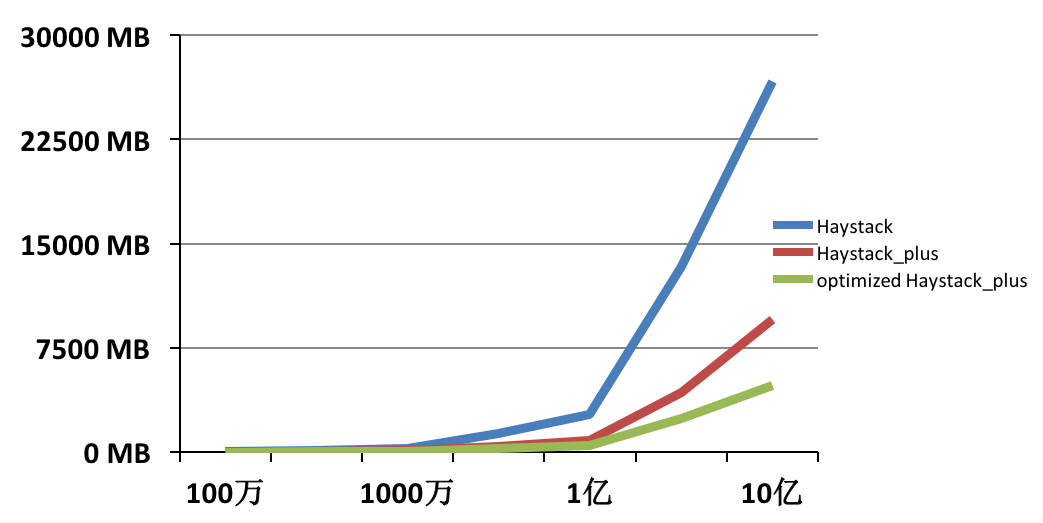
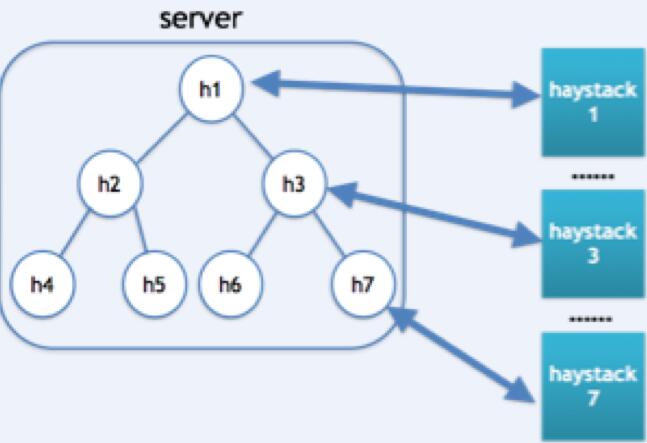
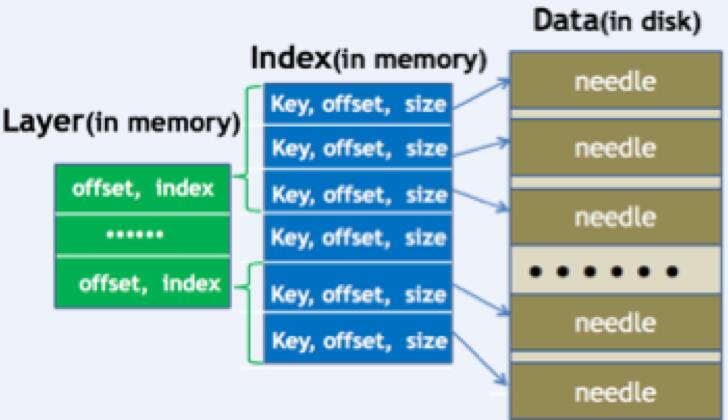
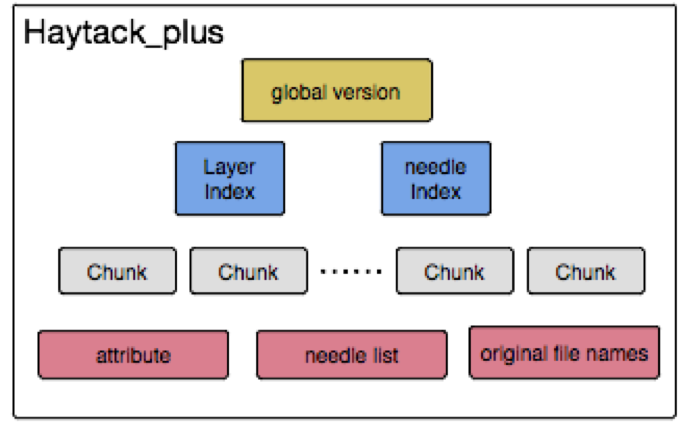
搭建一套redis集群用于测试,搭建过程如下
安装redis的ruby插件,用于构建redis集群。
gem install redis
下载最新的redis安装包:
wget http://download.redis.io/releases/redis-4.0.9.tar.gz编译安装(本次安装目录在/opt/redis目录下):
tar xzf redis-4.0.9.tar.gz
cd redis-4.0.9
make
make PREFIX=/opt/redis install
将构建集群的脚本拷贝至安装目录
cp src/redis-trib.rb /opt/redis/bin/制作集群配置文件(至少6个节点):
mkdir -p /opt/redis/cluster/{10001,10002,10003,10004,10005,10006}
echo "port {port}" > ./redis-cluster.conf
echo "dir /opt/redis/cluster/{port}" >> ./redis-cluster.conf
echo "cluster-enabled yes" >> ./redis-cluster.conf
echo "daemonize yes" >> ./redis-cluster.conf
echo "bind 127.0.0.1" >> ./redis-cluster.conf
sed 's/{port}/10001/' ./redis-cluster.conf > /opt/redis/redis-cluster-10001.conf
sed 's/{port}/10002/' ./redis-cluster.conf > /opt/redis/redis-cluster-10002.conf
sed 's/{port}/10003/' ./redis-cluster.conf > /opt/redis/redis-cluster-10003.conf
sed 's/{port}/10004/' ./redis-cluster.conf > /opt/redis/redis-cluster-10004.conf
sed 's/{port}/10005/' ./redis-cluster.conf > /opt/redis/redis-cluster-10005.conf
sed 's/{port}/10006/' ./redis-cluster.conf > /opt/redis/redis-cluster-10006.conf
启动节点:
/opt/redis/bin/redis-server /opt/redis/redis-cluster-10001.conf
/opt/redis/bin/redis-server /opt/redis/redis-cluster-10002.conf
/opt/redis/bin/redis-server /opt/redis/redis-cluster-10003.conf
/opt/redis/bin/redis-server /opt/redis/redis-cluster-10004.conf
/opt/redis/bin/redis-server /opt/redis/redis-cluster-10005.conf
/opt/redis/bin/redis-server /opt/redis/redis-cluster-10006.conf
关联成集群模式:
echo "yes" | /opt/redis/bin/redis-trib.rb create --replicas 1 127.0.0.1:10001 127.0.0.1:10002 127.0.0.1:10003 127.0.0.1:10004 127.0.0.1:10005 127.0.0.1:10006集群重启脚本:
PIDS=`ps -ef | grep '/opt/redis/bin/redis-server' | grep '127.0.0.1:1000' | awk '{print $2}'`
for i in $PIDS; do
echo "kill pid $i"
kill $i
done
sleep 3
rm -rf /opt/redis/cluster
mkdir -p /opt/redis/cluster/{10001,10002,10003,10004,10005,10006}
/opt/redis/bin/redis-server /opt/redis/redis-cluster-10001.conf
/opt/redis/bin/redis-server /opt/redis/redis-cluster-10002.conf
/opt/redis/bin/redis-server /opt/redis/redis-cluster-10003.conf
/opt/redis/bin/redis-server /opt/redis/redis-cluster-10004.conf
/opt/redis/bin/redis-server /opt/redis/redis-cluster-10005.conf
/opt/redis/bin/redis-server /opt/redis/redis-cluster-10006.conf
echo "yes" | /opt/redis/bin/redis-trib.rb create --replicas 1 127.0.0.1:10001 127.0.0.1:10002 127.0.0.1:10003 127.0.0.1:10004 127.0.0.1:10005 127.0.0.1:10006
PS: redis集群并没有考虑所有节点同时宕掉的情况,因此没有重启所有集群的命令,此重启脚本将所有数据情况,重建集群,请勿直接使用生产环境,仅限测试开发环境。