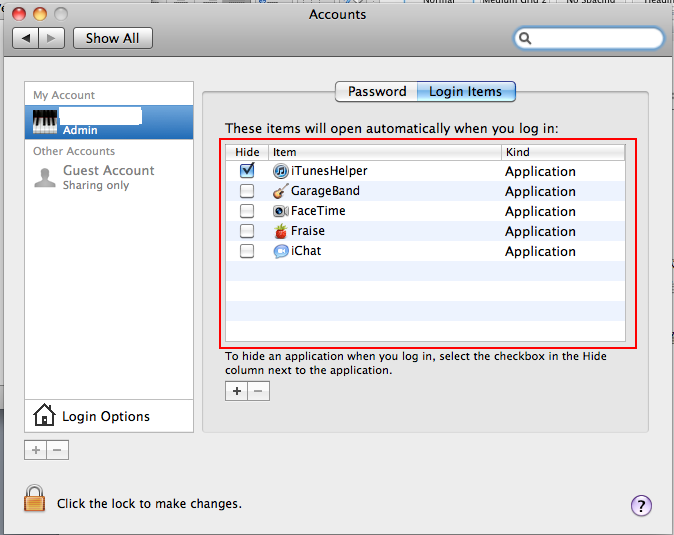
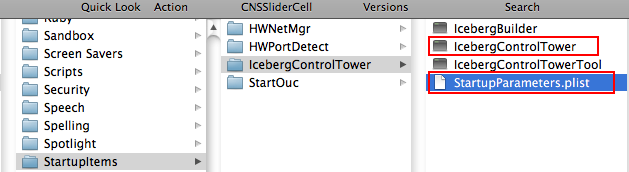
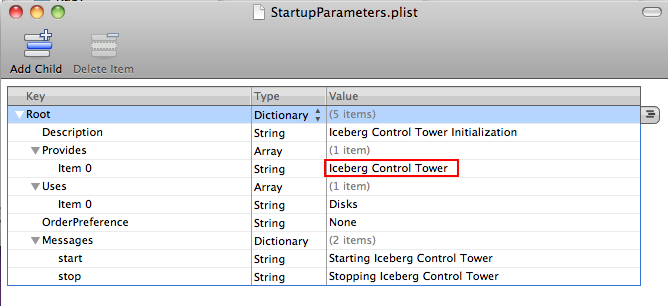
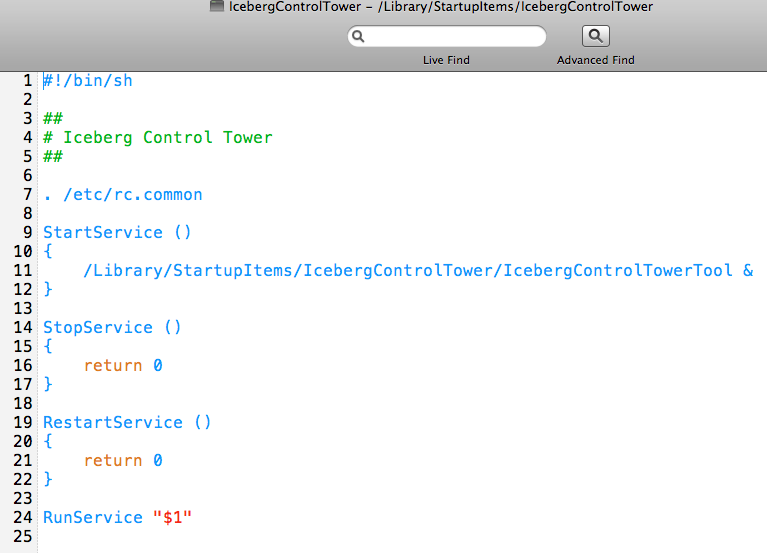
|
–module(tcp_listener).
–author(‘saleyn@gmail.com’).
–behaviour(gen_server).
–export([start_link/2]).
–export([init/1, handle_call/3, handle_cast/2, handle_info/2, terminate/2,
code_change/3]).
–record(state, {
listener, % Listening socket
acceptor, % Asynchronous acceptor’s internal reference
module % FSM handling module
}).
start_link(Port, Module) when is_integer(Port), is_atom(Module) ->
gen_server:start_link({local, ?MODULE}, ?MODULE, [Port, Module], []).
init([Port, Module]) ->
process_flag(trap_exit, true),
Opts = [binary, {packet, 2}, {reuseaddr, true},
{keepalive, true}, {backlog, 30}, {active, false}],
case gen_tcp:listen(Port, Opts) of
{ok, Listen_socket} ->
%%Create first accepting process
{ok, Ref} = prim_inet:async_accept(Listen_socket, –1),
{ok, #state{listener = Listen_socket,
acceptor = Ref,
module = Module}};
{error, Reason} ->
{stop, Reason}
end.
handle_call(Request, _From, State) ->
{stop, {unknown_call, Request}, State}.
handle_cast(_Msg, State) ->
{noreply, State}.
handle_info({inet_async, ListSock, Ref, {ok, CliSocket}},
#state{listener=ListSock, acceptor=Ref, module=Module} = State) ->
try
case set_sockopt(ListSock, CliSocket) of
ok -> ok;
{error, Reason} -> exit({set_sockopt, Reason})
end,
%% New client connected – spawn a new process using the simple_one_for_one
%% supervisor.
{ok, Pid} = tcp_server_app:start_client(CliSocket),
gen_tcp:controlling_process(CliSocket, Pid),
%% Signal the network driver that we are ready to accept another connection
case prim_inet:async_accept(ListSock, –1) of
{ok, NewRef} -> ok;
{error, NewRef} -> exit({async_accept, inet:format_error(NewRef)})
end,
{noreply, State#state{acceptor=NewRef}}
catch exit:Why ->
error_logger:error_msg(“Error in async accept: ~p.\n“, [Why]),
{stop, Why, State}
end;
handle_info({inet_async, ListSock, Ref, Error}, #state{listener=ListSock, acceptor=Ref} = State) ->
error_logger:error_msg(“Error in socket acceptor: ~p.\n“, [Error]),
{stop, Error, State};
handle_info(_Info, State) ->
{noreply, State}.
terminate(_Reason, State) ->
gen_tcp:close(State#state.listener),
ok.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
%% Taken from prim_inet. We are merely copying some socket options from the
%% listening socket to the new client socket.
set_sockopt(ListSock, CliSocket) ->
true = inet_db:register_socket(CliSocket, inet_tcp),
case prim_inet:getopts(ListSock, [active, nodelay, keepalive, delay_send, priority, tos]) of
{ok, Opts} ->
case prim_inet:setopts(CliSocket, Opts) of
ok -> ok;
Error -> gen_tcp:close(CliSocket), Error
end;
Error ->
gen_tcp:close(CliSocket), Error
end.
|